Churn Prediction

Olá a todos!
Nesse artigo vamos explorar o dataset de uma empresa de telecomunicações. Realizaremos uma análise exploratória para descobrirmos quais as principais características de um futuro cliente Churn.
Mas o que é Churn?!

Em si o Churn é o número total de clientes que, em um certo peródo de tempo, não querem mais comprar o produto de determinada empresa ou que não desejam mais utilizar do serviço prestado pela companhia. Essa rotatividade de clientes é algo constante e natural de qualquer negócio (Salesforce, Resultados digitais).
Indicador Churn Rate: taxa de rotatividade de clientes.
Toda empresa planeja e faz o máximo para ter o menor o Churn Rate possível e assim obter uma maior retenção de clientes. Já um Churn Rate alto indica que um maior número de clientes que cancelaram suas assinaturas(Salesforce).
Essas métricas são fundamentais para a sobrevivência de qualquer empreendimento nos dias atuais. De acordo com Philip Kotler, o pai da marketing, conquistar um novo cliente pode custar de 5 à 7 vezes mais do que manter os já existentes (GONÇALVES .H, 2007; Suno research) .
Portanto, se uma empresa quer garantir a permanência de seus consumidores, uma análise exploratória de dados ajudaria muito a identificar futuros clientes que não utilizaram mais seus serviços. Além disso, um modelo eficaz de machine learning poderia trazer resultados ainda melhores.

O objetivo deste artigo é realizar uma análise exploratória de um conjunto de dados (disponibilizado pela IBM) de uma empresa anonima de telecomunicações.
No próximo artigo estará toda a análise de previsão de um modelo de machine learning para pever os futuros clientes que pensam em desistir de suas assinaturas.

Ah tudo foi feito em linguagem de programação Python!!!
Neste link do GitHub está todo o primeiro capítulo do projeto, códigos, análise, conjuto de dados, construção dos gráficos e do modelo de machine leaning. Neste post inseri o conteúdo mais importante.
Bem, chega de introdução e vamos à análise!
A partir deste capítulo vamos identificar problemas em relação aos dados ausentes, outliers e entender melhor o problema que estamos envolvidos.
Conjunto de dados
Primeiramente, é necessário entendermos melhor a base de dados que será estudada. A base tem uma:

As 5 primeiras linhas de dados estão na imagem abaixo. Para uma melhor visualização dos elementos, separou-se em duas imagens.


As principais variáveis que trabalharemos são:
- tenure: quantos meses a pessoa assinou ou assina o plano;
- OnlineSecurity: utiliza o serviço de segurança/antivirus online (sim ou não);
- OnlineBackup: serviço de backup (sim ou não);
- DeviceProtection: dispositivo de proteção da rede contra tempestades (sim ou não);
- TechSupport: assina suporte técnico (sim ou não);
- TotalCharges: valor total pago desde o início até o dia atual do conjunto ou até o fim da assinatura (valor monetário);
- MonthlyCharges: valor do pacote no mês específico (valor monetário).
Obs: o período temporal do conjunto de dados é de 6 anos, pois o cliente mais velho a ter assinatura possui 72 meses na variável tenure.
É fundamental em qualquer conjunto verificar se existe dados ausentes, essa avaliação é feita abaixo.
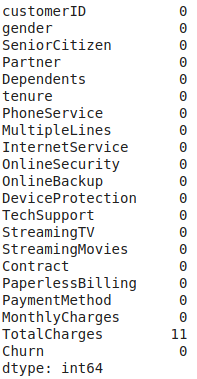
Nota-se que apenas a variável TotalCharges tem informações ausentes, sendo 11 entradas.
Vamos analisar os motivos desses dados ausentes!!!

Nas três linhas pode-se observar algo curioso, a variável tenure é representada como zero, isso indica que esses clientes ainda não têm nenhum mês de assinatura.
Portanto, os valores corretos em TotalCharges para essas linhas são zero e não ausentes. Substituindo os dados ausentes por zero, o conjunto não terá elementos faltantes.

Obtendo alguns insights do conjunto de dados
Uma boa pergunta para iniciarmos esse estudo é:
Qual é a quantidade de clientes que cancelaram seus planos e ainda mantêm suas assinaturas?!?
Essa análise é importante por dois motivos:
1ª: a coluna Churn é nossa variável dependente (alvo), sendo fundamental existir um balanceamento nas duas classes de dados(50% yes, 50% no);
2ª: a partir desse gráfico teremos a primeira ideia de como está a situação da empresa de telecomunicações, se ela tem uma boa retenção de clientes ou uma alta evasão.
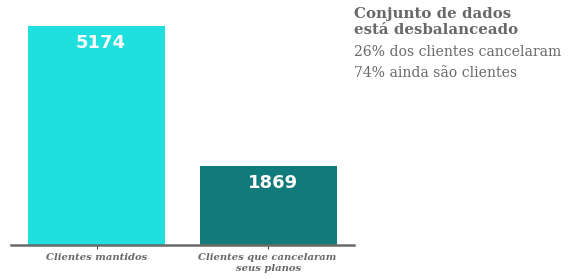
Nota-se que a variável Churn está desbalanceada, sendo prejudicial para um futuro modelo de machine learning, uma vez que a falta de proporção nas observações da variável alvo, fará com que o modelo não consiga aprender a prever a classe minoritária de dados.
obs: balanceamento será realizado no segundo o artigo no tópico de Machine Learning.
Já a situação da empresa em relação ao seus clientes, mostra um desempenho não tão positivo, pois 26% dos clientes nos últimos 6 anos cancelaram suas assinaturas.
No entanto, para termos uma melhor visão do impacto desses 1868 clientes, vamos ver quanto eles valiam financeiramente para empresa?!?
A figura abaixo representa os valores mensais em assinaturas ganhos e perdidos ao longo dos 6 anos da empresa.
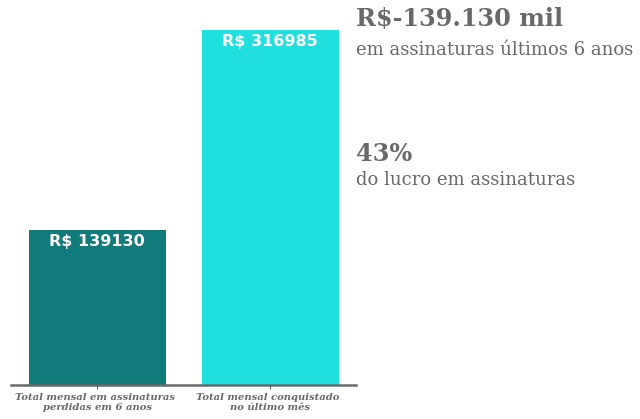
Financeiramente a empresa teve um alto prejuízo. Uma perda ao longo dos 6 anos que equivale 43% do lucro mensal atual. Olhando para esse aspecto percentual, é um valor considerávelmente alto para companhia.
Além de não estarmos considerando todo o valor perdido, que foi investido em marketing, vendas, TI etc para conquistar esses clientes que depois de um período de tempo cancelam seus planos.
Algo muito importante para checarmos é:
Quanto tempo a empresa tem para conquistar a admiração de um novo consumidor e mante-lo como um cliente fiél?!?

Podemos observar que:
- A maioria dos clientes desistem de sua assinatura após o primeiro mês;
- Até 5 meses há uma desistência de mais de 50 clientes;
- Nota-se que uma desistência a qualquer período de uso, pois mostra cancelamentos de até 72 meses.
Esse resultado mostra o grande desafio que esta empresa de telecomunicações aguarda pela frente. A companhia tem poucos meses até identificar um cliente Churn e aplicar alguma metodologia e benefícios para reter esse consumidor.
Porém, é evidente que investir dinheiro para manter esse novo usuário é muito menos custoso do que perdê-lo e investir na busca de um novo. Ou melhor, porque não garatir esse cliente e posteriormente investir o lucro deste na conquista de um novo cliente ao mesmo tempo.
Vamos dar uma olhada em coisas boas também!!!
A quanto tempo a maioria dos clientes fiéis a empresa tem seus contratos?!?

Já nesse histograma nota-se que:
- Mais de 500 clientes já estão com seus a planos há 6 anos, mostrando que exitem clientes que admiram e gostam dos benefícios dos serviço da empresa.
- Nos últimos 4 meses teve uma crescente ascensão de clientes novos.
Qual é a distribuição dos valores mensais de assinatura?!?
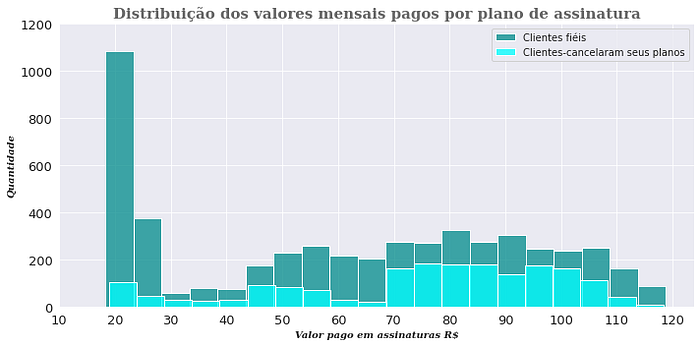
Observa-se uma tendência semelhante dos dois tipos de clientes, porém, em uma escala de menor quantidade para os clientes Churn.
- Churn: a maior frequência de assinaturas dos planos são de valores de R$ 70 até 100;
- Clientes fiéis: Aproximadamente 1100 clientes assinam um pacote do valor entre R$ 20 e 25. Percebe-se uma alta frequência nos valores de R$ 50 até 110.
Dos clientes que utilizam de algum pacote de proteção como DeviceProtection, OnlineSecurity, OnlineBackup, TechSupport possuem uma menor chance de cancelarem seus planos?
Quem utiliza serviço de proteção tem uma maior probabilidade de não desistir de suas assinaturas?!?
Para responder essa pergunta, realizaremos 8 gráficos de barras.
Os 4 primeiros gráficos abaixo, são referentes aos clientes que não utilizam destes serviços.

Os 4 próximos gráficos são em relação aos clientes que utilizam algum serviço de segurança.

Através destes dois conjuntos de gráficos, podemos afirmar que se um consumidor utiliza um dos serviços de proteção, ele tem uma menor probabilidade de se tornar Churn, sendo essa diferença de 22%.
Que tal fazermos um boxplot das variáveis contínuas. Assim podemos ver a existência de Outliers.

Percebe-se que não há nenhum outlier no conjunto de dados. Caso houvesse seria prejudicial para o modelo de machine learning.
Estamos chegando quase ao fim desse primeiro artigo!!!

Conclusão
Depois dessa análise rápida podemos concluir alguma hipóteses.
Em relação ao conjunto de dados pode-se afirmar que:
- A variável dependente Churn está desbalanceada;
- Não há dados ausentes e nem outliers;
- Existe variáveis categóricas o tipo string que não são aceitas para o modelo de machine learning.
Já em relação a situação da companhia podemos perceber alguns pontos:
- A empresa teve um alto cancelamento de assinaturas nos 6 anos de avaliação;
- E o pior desse alto cancelamento foi que a valor perdido em assinaturas foi muito alto, chegando a 43% do lucro atual.
- A maioria dos clientes Churn desistem da assinatura após o primeiro mês, tendo um pequeno espaço de tempo para identificar e conquistar o cliente;
- A empresa também tem clientes fiéis que já estão a mais de 6 anos com suas assinaturas.
Claro que para ajudar em todo esse problema, um bom modelo de machine learning para prever quem são os clientes Churn pode trazer muitos ganhos. Assim a companhia pode reconhece-lo no menor tempo possível e buscar soluções para mantê-los como um cliente fiel.
Agradecimentos como revisora: Talita Velozo Rodrigues
A próxima parte desse artigo será totalmente voltada para a criação de um modelo de machine learning.
OBS: A parte de Machine Learning está sendo finalizada e será disponibilizada futurmamente.

